
ZFS and caching for performance
Updated:
Note : This page may contain outdated information and/or broken links; some of the formatting may be mangled due to the many different code-bases this site has been through in over 25 years; my opinions may have changed etc. etc.
I’ve recently been experimenting with ZFS in a production environment, and have discovered some very interesting performance characteristics. I have seen many benchmarks indicating that for general usage, ZFS should be at least as fast if not faster than UFS (directio not withstanding - not that UFS directio itself is any faster, but anything that does it’s own memory management such as InnoDB or Oracle will suffer from the double-buffering effect unless ZFS has been tuned appropriately), but nothing prepared me for what I discovered in my preliminary benchmarking.
To give a little background : I had been experiencing really bad throughput on our 3510-based SAN, which lead me to run some basic performance tests and tuning. During the course of this (and resolving some of the issues), I decided to throw ZFS into the mix. The hosts involved are X4100s, 12Gb RAM, 2x dual core 2.6Ghz opterons and Solaris 10 11/06. They are each connected to a 3510FC dual-controller array via a dual-port HBA and 2 Brocade SW200e switches, using MxPIO. All fabric is at 2Gb/s.
So far, pretty straightforward. I had been using iozone as my benchmarking tool (using a 512Mb file as that’s the average table size for our databases), and compared a wide range of systems and configurations, from an Ultra 20 with 7200RPM SATA drives, to the X4100’s internal 10K RPM SAS disks as well as LUNs made available from the SAN in a variety of RAID levels.
Some interesting results here, which I’ll skip over for the moment (like the Ultra20 beating the X4100 and SAN in read performance!) - the kicker happens when I added ZFS into the mix as an experiment. On average, I ended up seeing an average rate on the non-ZFS volumes depending on how they were configured, on average I was seeing 65MB/s write performance and around 450MB/s read on the SAN using a single drive LUN. This was faster if I used a stripe, slower if I used RAID 5, pretty much what you’d expect. Also everything seemed to get capped out at the theoretical maximum of 2x2Gb/s channels (around 512MB/s). So far, so normal… Here’s my results for write performance, for a basic comparison :
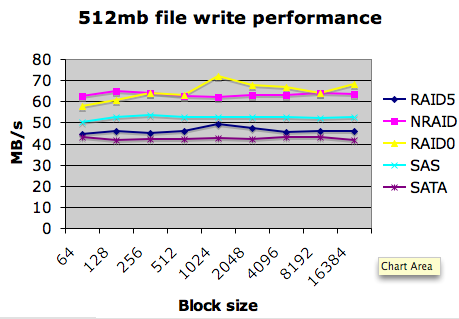
I then tried ZFS, and immediately started seeing a crazy rate of around 1GB/s read AND write, peaking at close to 2GB/s. Given that this was round 2 to 4 times the capacity of the fabric, it was clear something was going awry. I was also particularly wary as there was no discernable write performance hit. I tried ZFS on a single drive, ZFS striped and RAIDZ across multiple "JBOD" LUNS, then finally ZFS on top of a LUN striped at the array. Same insane results each time - here’s what I saw, leaving the old results in as a base :
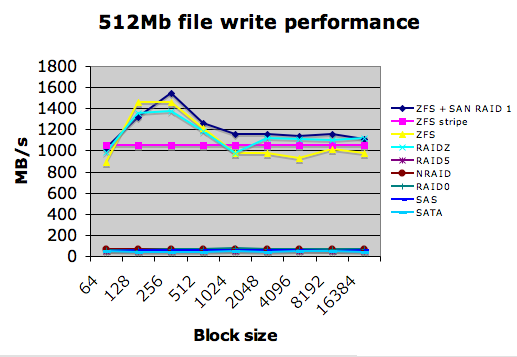
Whoah. I then checked what was going on at the fabric level, and I saw something that was very interesting. Using mkfile for instance, I could create a 2GB file on a ZFS filesystem made on top of a SAN LUN in around 1.5 seconds. (which thrashes the poor UFS performance we were getting from our 3510). After that, I can do a "ls -lh" and see it, and it seems to be there. However, iostat and "zpool iostat" showed a different story.
Despite ZFS saying the file was there, for several seconds afterwards I could see data emptying out over the SAN to the array at a rate that was pretty much the same as my other tests, and iostat reported a 100% utilisation for the underlying volume for a ahort while afterwards. I went back to iozone and use the -e flag to issue a fsync() after the writes, this brought things down to a level that I expected as far as write performance is concerned but read performance still was insanely high.
So what seems to be happening is that ZFS is caching extremely aggressively - way more than UFS, for instance. Given that most of the "I/O" was actually happening straight to and from the ARC cache, this explained the phenomenal transfer rates. Watching iostat again also showed that during the read tests, I was using far less of the SAN bandwidth. While performing "read" iozone tests on UFS, I was nearly maxing out the fabric bandwidth which could have lead to resource starvation issues, both for the host running the tests and for other hosts sharing the SAN. Using ZFS, the bandwidth dropped down to 50MB/s or so at peak, and much lower for the remainder of the tests - presumably due to the caching and prefetch behaviour of ZFS.
The upshot of all this is that it seems ZFS is just as "safe" as UFS - any application that really wants to be sure data has been written and committed to stable storage can still issue a fsync(), otherwise writes to the disks still happen at around the same rate as UFS, it just gives control back to the application immediately and lets the ZFS IO scheduler worry about actually emptying the caches. Assuming I lost power half-way through these writes, the filesystem would still be guaranteed to be safe - but I may still loose data (data loss as opposed to data corruption, which ZFS is designed to protect against end-to-end). It can also give you a staggering performance advantage and conserve IO bandwidth, just so long as you’re careful you don’t get misled into believing that your storage is faster than it actually is and have enough memory to handle the caching!
Many thanks to Greg Menke and Tim Bradshaw on comp.unix.solaris for their help in unravelling this mystery !
The opinions and views expressed on this website are my own and do not necessarily reflect the views of my employer, past or present.