
DevOps for the Sinclair Spectrum - Part 2
Updated:
This article is part of a series
- Table Of Contents - Full table of contents in Part 1
- Part 1 - Introduction, hardware, development environment, Windows/Linux buildchain and tools
- Part 2 - The server environment and building the first prototype
- Part 3 - The backend server daemon, pipelines and unit tests
- Part 4 - Wrap-up, other sites and final thoughts
In Part 1, I explored the hardware and development environment. In this article, I’ll cover the server-side components as well as coding and launching the first iteration of the site along with some of the limitations I encountered when programming on such an old system.
Server environment

USAGELOG=yes to the make arguments.
I can run this binary with a simple systemd unit file on my Linux systems:
[Unit]
Description=TNFSD Service
ConditionPathExists=|/usr/bin
After=network.target
[Service]
User=root
ExecStart=/usr/local/bin/tnfsd /data/tnfs -c tnfsd
RestartSec=3
Restart=always
[Install]
WantedBy=multi-user.targetNote the -c tnfsd argument to the binary; this is used to chroot to the server directory and drop privileges to another un-privileged user account. This is obviously a must-have if you’re in any way exposing these services to the internet.
I have also built a Docker/OCI image for tnfsd so I can run the backend from a Kubernetes cluster, you can grab it from markdr/tnfsd. Usage is simple, you just have to expose the UDP port and map in a directory containing your TNFS “docroot”:
docker run --rm -d \
-v $PWD:/data \
-p 16384:16384/udp \
markdr/tnfsdThe production site components are running on a Digital Ocean droplet and managed Kubernetes cluster, and for my development work I have a dev/test TNFS server on my local LAN. This is a HP Microserver that runs Ubuntu 20.04, along with a Kubernetes cluster that I use as a central “control plane” type environment for handling CI/CD and provisioning/monitoring my other (mostly work-related) VMware/NSX DKP Kubernetes systems. More about all that later…
Environments
To help in quickly switching between environments, I added a “hidden” key-press to the site main menu. This just switches to the Spectranet TNFS filesystem slot #3 (which I always leave connected to my local dev server) and then boots from that. All my Spectrums (emulated, or physical) with Spectranets are configured to boot into the production site, so I just have to hit Shift-L to switch into local “dev mode”.
As the build process happens inside OCI containers, I can set some environment variables and run a simple shell script to substitute placeholders (like _API_SERVER_ for the TNFSD server hostname) in my source code. For example, this is how the main menu gets built:
#!/bin/bash
sed "s/_API_SERVER_/$API_SERVER/g; \
s/_BUILD_/$BUILD/g; \
s/_GIT_REV_/$GIT_REV/g" menu.bas > out/menu.bas
zmakebas -a 10 -l -o out/menu.zx out/menu.basThis way, I can parameterize my build environments. My “production” environment for example, is configured with the following variables:
API_SERVER=tnfs.markround.com
BUILD=Production
GIT_REV="$(git log --pretty=format:'%h' -n 1)"Which results in some of the values displayed in my debug screen, shown below running on the real hardware.

The Minimal Viable Product
Working in a professional capacity at $DAYJOB, I’ve seen first-hand the value in getting a basic prototype released as early as possible and gathering user feedback. A product doesn’t have to be “finished” or even polished, it just needs to provide value and then you can iterate on it, add features and adjust course as necessary. While I’ve since added a bunch of features to the site (with lots more on my backlog) and the codebase has been through several versions, I had a pretty good idea of what would constitute a MVP: I just needed some sort of menuing system and a way of selecting from a collection of hosted files so users could play games, watch demos, read tape magazines and so on.
Menu and files
Building a menu system was the simplest part of coding the site. I’d done this many times in my youth and remembered the steps well enough including the trick of using the pause statement to wait until a key is pressed then reading it’s value with inkey$. Whilst interpreted BASIC code on a 3.5Mhz computer is really slow, I still managed to include a rudimentary scroll-text at the bottom of the screen and add audio feedback so menu choices registered a beep sound from the Spectrums speaker - one of the first features I added that was suggested by a user of the site.
What was more of a challenge was working out how to present a list of files to the user so they could pick a game or demo to play. Remember, this is Spectrum BASIC designed around a computer that loaded programs from a cassette tape; There’s no mass storage available to us, no Dir.glob() function or anything like that.
My first iteration of this was very simple - I used a script in my WSL2 shell to rename all the files, stripping out odd characters and truncating the filename so that it would fit on the Speccy’s screen. I then used the same shell script to loop over all the files in a directory and output data statements in BASIC with the “presentable” filename stored along with the path and title in uppercase for searching later, which resulted in something like this:
...
data "Absent","/demos/a/Absent.tap","ABSENT"
data "Abstraction","/demos/a/Abstraction.tap","ABSTRACTION"
data "Acheron","/demos/a/Acheron.tap","ACHERON"
...
data "_STOP_","",""I just appended the output of this script to the end of my zmakebas source code from the build script.
On the Spectrum, this could be iterated through with the aid of the read command and the “pointer” reset with the restore command, as long as I stored the data statements starting from a known line-number. I picked 9000 in this case as it was a safe bet that I’d never write 9000-odd lines of preceeding code before it!
Lists
Allocating new session for 0x00
Allocated new session for 0x95d0
2022-01-10 09:54:52|192.168.0.18|SID=95d0|Session started at: /
2022-01-10 09:54:54|192.168.0.18|SID=95d0|File mounted: /boot.zx
2022-01-10 09:54:54|192.168.0.18|SID=95d0|File mounted: /header.tap
2022-01-10 09:54:54|192.168.0.18|SID=95d0|File mounted: /menu.zx
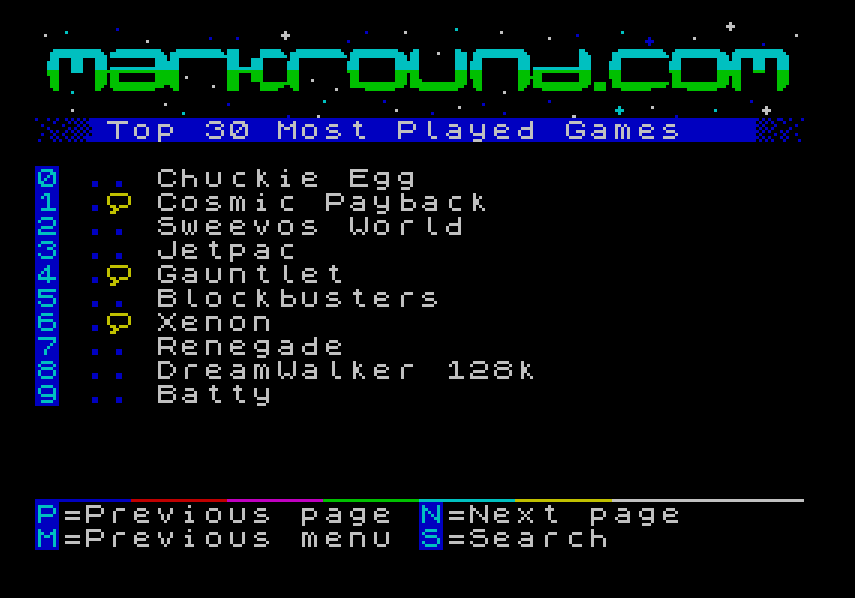
It’s very easy to extract information from that using a pipeline of standard Unix commands; To get the top 30 most played games for example, I used something like this:
grep 'File mounted: ' /data/tnfsd.log \
| awk '/\/games\//{print $4}' \
| sort \
| uniq -c \
| sort -nr \
| head -n 30 \
| awk '{print $2}'I could then use that in a shell script to build up a set of data statements, formatted to my standard and append them to a “Hall Of Fame” menu system.
Release Early, Release Often
Speedbumps
But still, I had rapidly hit the limits of what I could realistically do with pure Sinclair BASIC. These speedbumps on the road to 1.0 ultimately led me to create the Ruby-based containerised backend service running on Linux (which I cover in Part 3) but to give you an idea of the brick walls I was banging into, I had to pre-calculate the file title in uppercase to make case-insensitive searching possible.
Once again, I’ve been spoiled by modern conveniences and there’s no nice str.upper() that we can throw in loops without thinking twice. Even a simple routine like this made the approach unusably slow to use inside a loop:
REM convert input to uppercase
let u$=""
for i=1 TO LEN (i$)
let b=code (i$(i))
if b>=97 and b<=122 then let b=b-32
let u$=u$+CHR$ (b)
next i
let s$=u$Running this loop-within-a-loop proved to be far too costly in terms of CPU cycles, Sinclair BASIC again is jarringly limited by the standards of today’s languages. I’m sure there was probably a more efficient way to do this but I chose the least-effort solution of “pre-calculating” the values. My search code to find the first partial match could then look something like this:
input "Search> "; line i$
gosub @uppercase
restore 9000
REM Assuming that there will never be more than 1,000 entries for a given category
for s = 0 to 1000
read d$,f$,x$
if d$ = "_STOP_" then let s = 1000 : next s : pause 1000 : goto @nomatches
if len(s$) < len(x$) then let x$=x$( to len(s$))
if x$=s$ then let start=s: let s=1000: next s: goto @found
next sNote another “how did we live like this?!” deficiency in Sinclair BASIC: There’s no break statement to get out of for loops. Instead, to avoid memory leaks you have set the iterator to the last range value and terminate the loop by hand.
Still, all this worked well enough for a while but I soon hit other limits like a hard and surprisingly easy to hit restriction on the number of data statements in a BASIC file I could add before running out of memory.
Yup, turns out 48Kb is actually far too pokey to use a modern “CPU cycles and storage is cheap” mentality. I pushed the system as far as it would go, but when I started having to split file listings over dozens of files, I decided to shift the CPU and storage burden instead to somewhere it was cheap - I could use the Spectranet’s streams extension to make TCP calls to a service running on the Internet. This would also let me add some really cool features and expand the capabilites far beyond a stand-alone BASIC program.
In Part 3, I’ll talk about how I overcame these problems by implementing a Linux-based server API, and what my CI/CD deployment and unit testing processes look like.